
The landscape of artificial intelligence is rapidly evolving, with language models at the forefront of innovation. Recent breakthroughs have led to the development of increasingly sophisticated models capable of understanding, generating, and processing human language with unprecedented accuracy and fluency.
Two of the most prominent advancements in this space are GPT-4o Mini and Llama 3.1 8B. These large language models (LLMs) represent significant leaps forward in natural language processing (NLP), demonstrating remarkable capabilities in various applications.
This article delves into the intricacies of GPT-4o Mini and Llama 3.1 8B, exploring their architectures, performance, potential applications, and the implications for the future of AI. By examining these cutting-edge models, we aim to shed light on the rapid advancements in natural language processing and their transformative impact on industries and society.
Deep Dive into Model Architecture and Improvements
Understanding the Transformer Architecture
Before delving into the specifics of GPT-4o Mini and Llama 3.1 8B, it’s essential to grasp the foundational architecture of these models: the transformer. Introduced in the paper “Attention Is All You Need,” the transformer architecture has revolutionized natural language processing. It eschews recurrent neural networks (RNNs) in favor of an attention mechanism that allows the model to weigh the importance of different parts of the input sequence.
Key components of a transformer:
- Encoder-decoder Architecture: For tasks like machine translation, the encoder processes the input sequence, while the decoder generates the output sequence.
- Self-attention Mechanism: Enables the model to focus on different parts of the input sequence, capturing dependencies and relationships.
- Multi-head Attention: Allows the model to learn multiple representations of the input data.
- Positional Encoding: Incorporates information about the position of words in the input sequence.
- Feed-forward Neural Networks: Process the output of the attention layers.
- Layer Normalization: Stabilizes training and improves performance.
GPT-4o Mini: A Glimpse into the Architecture
While specific details about GPT-4o Mini’s architecture are limited, we can make educated inferences based on the GPT series. It is likely a scaled-down version of its larger counterpart, GPT-4, with fewer parameters and layers. Key architectural components might include:
- Transformer Decoder: Generates text sequences based on the provided input.
- Self-attention: Enables the model to focus on different parts of the input sequence.
- Feed-forward Neural Networks: Process the output of the self-attention layers.
- Layer Normalization: Stabilizes training and improves performance.
- Number of Layers: Estimated to be fewer than GPT-4, potentially around 24-36 layers.
- Number of Parameters: Likely in the range of tens of billions of parameters.
Llama 3.1 8B: Architectural Details
Meta AI has provided more transparency about the Llama model architecture. Llama 3.1 8B builds upon its predecessors’ foundation, incorporating efficiency and performance improvements. Key architectural components include:
- Transformer Decoder: Generates text sequences based on the provided input.
- Rotary Positional Embeddings: A Novel Positional Encoding Technique for Handling Long Sequences.
- Attention Mechanisms: Optimized attention mechanisms for faster computation and improved performance.
- Quantization: Techniques to reduce model size and computational requirements without significant performance degradation.
- Number of Layers: 32 layers.
- Number of Parameters: Approximately 8 billion parameters.
Visualizing Model Architecture
These diagrams provide a visual representation of the core components of transformer-based models.
Performance Benchmarks and Improvements
To quantitatively evaluate the performance of GPT-4o Mini and Llama 3.1 8B, it’s essential to compare them against previous models and established benchmarks. While direct comparisons might be limited due to proprietary nature and varying evaluation metrics, general trends and potential improvements can be inferred.
Benchmark Datasets
Several benchmark datasets are commonly used to evaluate the performance of language models:
- GLUE (General Language Understanding Evaluation): A collection of tasks designed to evaluate a model’s ability to understand and reason about language.
- SQuAD (Stanford Question Answering Dataset): Evaluates a model’s ability to answer questions based on a given passage of text.
- SuperGLUE: A more challenging benchmark than GLUE, designed to evaluate advanced language understanding capabilities.
- CommonSenseQA: Evaluates a model’s ability to reason about common sense knowledge.
- HumanEval: Evaluates a model’s ability to write correct code.
- MMLU (Massive Multitask Language Understanding): A benchmark covering a wide range of tasks, including question answering, summarization, and translation.
- C4 (Common Crawl): A massive dataset used for training large language models.
Specific Improvements
Based on the available information and general trends in language model development, we can expect GPT-4o Mini and Llama 3.1 8B to exhibit the following improvements:
- Increased accuracy: Higher scores on benchmarks like GLUE, SQuAD, and SuperGLUE indicate better understanding of language and improved ability to perform tasks like question answering, text summarization, and sentiment analysis.
- Reduced hallucinations: Lower rates of generating nonsensical or irrelevant text, enhancing the model’s factuality and reliability.
- Enhanced coherence: Improved ability to generate text that is logically consistent and flows smoothly, making the output more human-like.
- Better handling of complex prompts: Ability to understand and respond to nuanced and ambiguous prompts, demonstrating improved reasoning capabilities.
- Improved factual grounding: Reduced tendency to generate incorrect or misleading information, enhancing the model’s reliability and trustworthiness.
Researchers and developers can gain valuable insights into their capabilities and limitations by carefully evaluating these models on various benchmarks and analyzing their performance metrics.
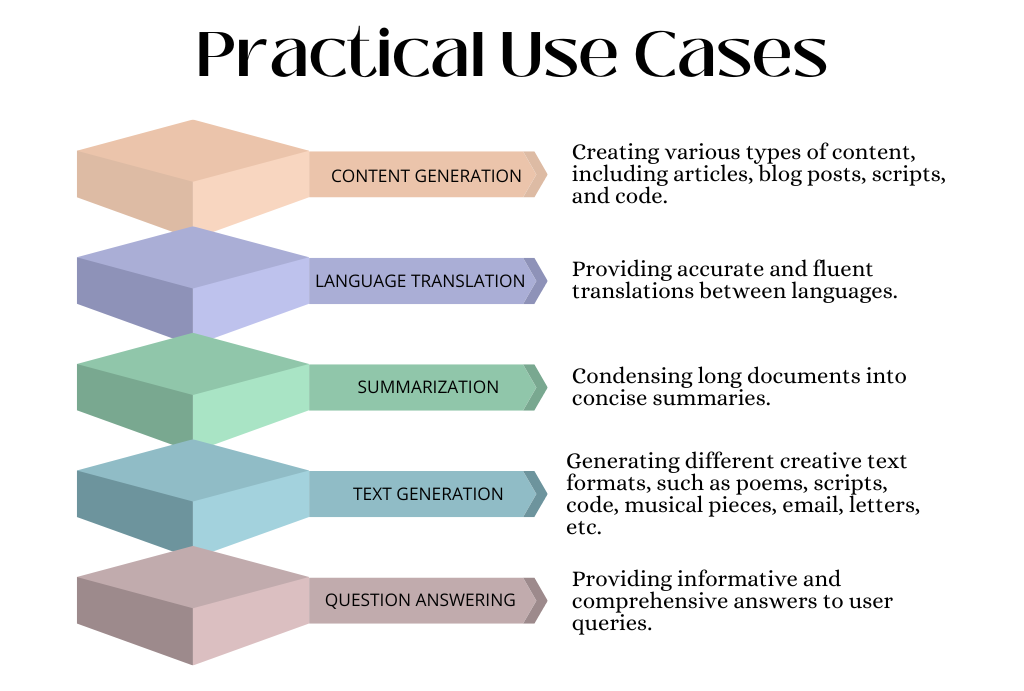
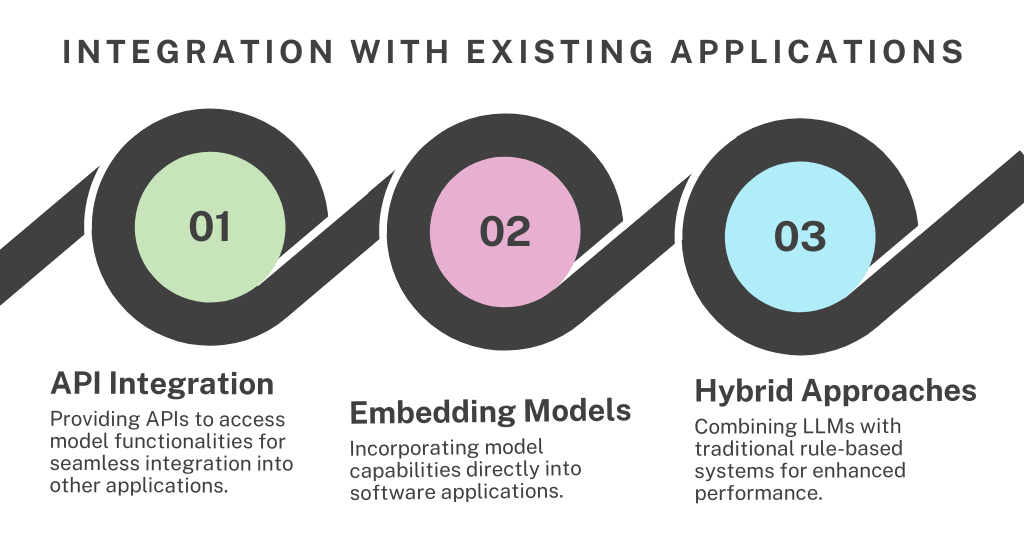
Challenges and Limitations
Despite significant advancements, GPT-4o Mini and Llama 3.1 8B, like their predecessors, encounter several challenges and limitations. Addressing these issues is critical for the responsible and effective deployment of large language models.
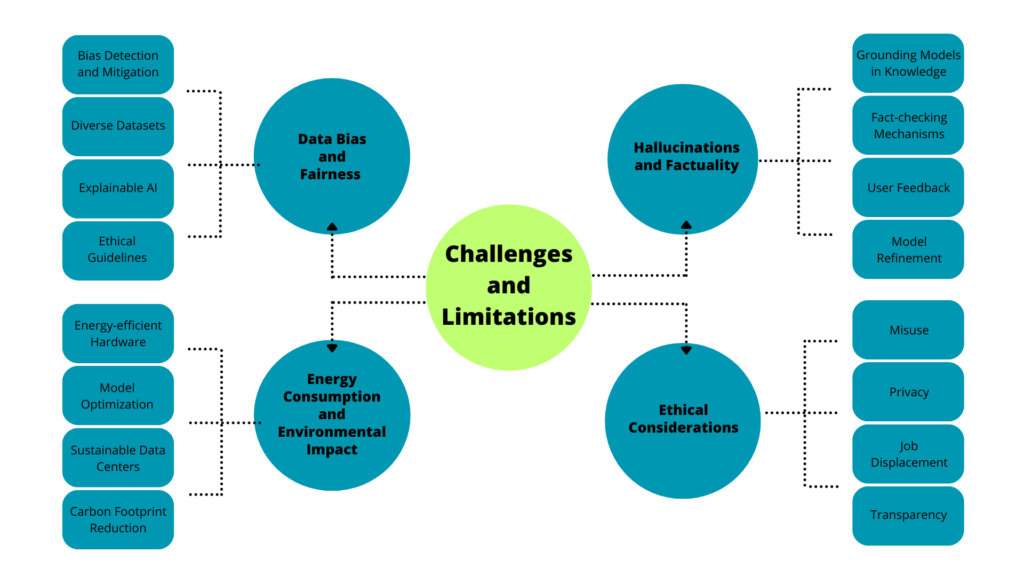
Data Bias and Fairness
Language models are trained on massive datasets that often reflect societal biases. This can lead to models generating discriminatory or biased content. To mitigate this issue, researchers and developers are focusing on:
- Bias Detection and Mitigation: Developing techniques to identify and reduce biases in training data and model outputs, such as adversarial training and fairness metrics.
- Diverse Datasets: Curating training data that represents diverse populations and perspectives.
- Explainable AI: Understanding the decision-making process of models to identify potential biases.
- Ethical Guidelines: Establishing clear ethical principles for model development and deployment.
Hallucinations and Factuality
While LLMs have improved in generating coherent and informative text, they still exhibit tendencies to produce incorrect or misleading information, known as hallucinations. To address this challenge:
- Grounding Models in Knowledge: Connecting models to external knowledge bases or search engines to improve factual accuracy.
- Fact-checking Mechanisms: Integrating robust fact-checking systems to verify generated content.
- User Feedback: Incorporating user feedback to identify and correct errors.
- Model Refinement: Continuously improving models through reinforcement learning from human feedback (RLHF).
Energy Consumption and Environmental Impact
Training and running large language models require substantial computational resources, contributing to carbon emissions. To mitigate this:
- Energy-efficient Hardware: Utilizing specialized hardware designed for AI workloads.
- Model Optimization: Developing techniques to reduce model size and computational requirements, such as quantization and pruning.
- Sustainable Data Centers: Partnering with data centers that prioritize renewable energy.
- Carbon Footprint Reduction: Implementing strategies to minimize the environmental impact of model training and inference.
Ethical Considerations
The development and deployment of LLMs raise significant ethical concerns, including:
- Misuse: Preventing the use of LLMs for malicious purposes, such as generating harmful content or spreading misinformation.
- Privacy: Protecting user data and ensuring compliance with privacy regulations.
- Job Displacement: Assessing the potential impact of LLMs on the workforce and developing strategies for workforce adaptation.
- Transparency: Providing clear information about model capabilities, limitations, and biases.
Future Trends and Implications
The rapid advancement of LLMs like GPT-4o Mini and Llama 3.1 8B signals a new era of artificial intelligence. Several key trends and implications are likely to emerge:
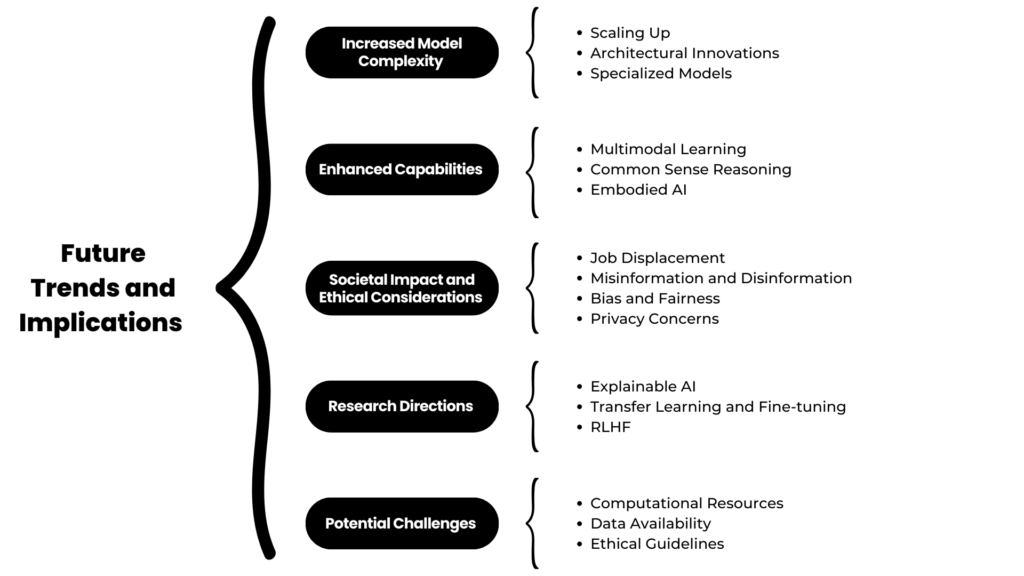
Increased Model Complexity
- Scaling Up: Future models will likely explore even larger parameter counts, potentially reaching trillions of parameters.
- Architectural Innovations: New architectural designs and techniques will be developed to improve efficiency and performance.
- Specialized Models: Models tailored for specific tasks, such as medical diagnosis or code generation, will become more prevalent.
Enhanced Capabilities
- Multimodal Learning: LLMs will be able to process and generate multiple modalities of data, including text, images, and video.
- Common Sense Reasoning: Improved ability to understand and reason about the world, leading to more human-like interactions.
- Embodied AI: Integration of language models with physical agents for real-world interaction.
Societal Impact and Ethical Considerations
- Job Displacement: Automation of tasks traditionally performed by humans will lead to changes in the workforce.
- Misinformation and Disinformation: The potential for misuse of LLMs to generate misleading or harmful content.
- Bias and Fairness: Addressing biases in training data and model outputs to ensure equitable outcomes.
- Privacy Concerns: Protecting user data and maintaining privacy while developing and deploying LLMs.
Research Directions
- Explainable AI: Developing techniques to understand and interpret the decision-making process of LLMs.
- Transfer Learning and Fine-tuning: Improving the efficiency of training new models by leveraging pre-trained models.
- Reinforcement Learning from Human Feedback (RLHF): Enhancing model performance through human-in-the-loop training.
Potential Challenges
- Computational Resources: The increasing size and complexity of LLMs will require significant computational power and energy.
- Data Availability: Access to high-quality and diverse datasets will be crucial for model development.
- Ethical Guidelines: Developing and enforcing ethical standards for AI development and deployment.
The future of LLMs holds immense potential, but it is essential to address the associated challenges and ethical considerations to ensure responsible and beneficial development.
Conclusion
The emergence of GPT-4o Mini and Llama 3.1 8B marks a significant milestone in the evolution of language models. These advanced models demonstrate remarkable capabilities, from understanding and generating human-quality text to performing complex tasks across various industries.
While these models offer immense potential, it is essential to address the associated challenges, such as bias, misinformation, and ethical considerations. Responsible development and deployment are crucial for harnessing the benefits of LLMs while mitigating risks.
As technology continues to advance, we can anticipate even more sophisticated language models with expanded capabilities. The future of AI lies in the development of models that can seamlessly integrate into our lives, providing valuable assistance and enhancing human potential.
At Codersperhour, we are at the forefront of AI research and development. Our expertise in language models enables us to create innovative solutions that drive business growth and improve human experiences. Contact us to explore how we can help you harness the power of LLMs.